一次情報に基づく独自の調査・研究レポート
4ワークロード独自試算で見るサブスクとAPIの損益分岐、競合LLM横並び比較、規約上の盲点
Claude Max x20 ($200/月) の真のコスパを4ワークロード独自シミュレーションで検証。損益分岐は月150-200Mトークン。「コスパ28倍」はキャッシュ無視の最大値で、実態は3-7.5倍。cron・自動化はMax対象外。プロンプトキャッシュ構造、ChatGPT Pro / Gemini との横並び、移行判断フローまで完全公開。
7つの最新LLMに日本語能力試験を解かせ、さらに問題を作らせた。「解ける」と「作れる」は全く別の能力だった。
7つのフロンティアLLMにJLPT問題の解答と生成を要求。Claude Opus 4.6が総合1位(92.7%)、全モデルでハルシネーション検出。敬語カテゴリのハルシネーション率35%が最大の弱点。
同一情報・5文体・3モデルで検証する「読みやすさ」の非対称性
LangChain失速、LiteLLM急伸 ── コミット数から読み解くAIエコシステムの構造変化
GitHub APIの実データで主要AI系OSS 10プロジェクトを分析。LiteLLMはコミット数+81%で爆発的成長、一方LlamaIndexは-55%、AutoGenはQ4コミット数ゼロで事実上の開発停止。インフラ層の台頭とオーケストレーション層の衰退を定量的に検証した。
Claude Opus 4.5・GPT-5.2・Gemini 3 Proで独自実験
AIに敬語を使うと回答は変わるのか? 3つの最新LLMで実験した結果、命令形は敬語の半分以下のトークンで回答を完了し、年間$15,000の節約が可能であることが判明。先行研究との比較も交え、プロンプトの「言い方」の影響を定量的に検証した。
日本と世界の最新データが示す「テクノロジーと幸福の不均衡」
AIの急速な社会浸透は人間の幸福度にどう影響しているのか。Pew Research、博報堂、JILPT、IMF、世界銀行の最新調査データを横断的に分析し、日本を軸にグローバル比較を行う政策立案者向け調査レポート。
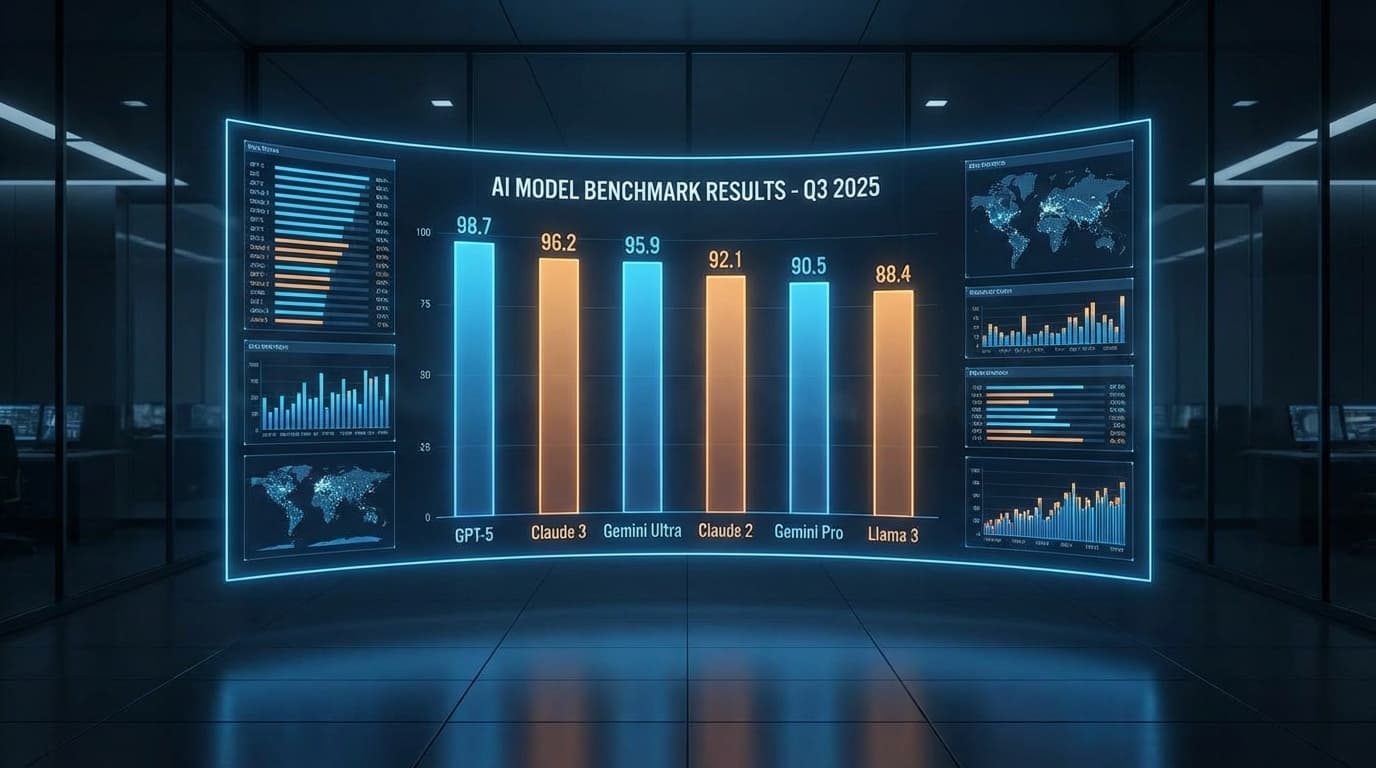
ベンダー中立・実測主義のAIモデル評価
6大モデル × 5タスク × 200試行 — 全データ公開
AI Sovereigntyが経営課題となった2026年、日本企業はどう動くべきか
IBM IBV調査で経営幹部の93%が「AI主権を戦略に組み込む必要がある」と回答。データ・モデル・インフラの3層で日本企業の依存構造を分析し、EU AI Act対応コストの定量化、国産LLMの実力評価、そして現実的な5つのアクションを提示する。
GPT-5.2が1位だが、設定ミスで性能ゼロ — AIエージェントの「幻滅の谷」を検証
Gartnerのハイプサイクルで「過度な期待のピーク」にあるAIエージェント。タオリス人機和総研が6つの最先端モデルで150回の実験を行った結果、全試行の20%でコンテンツ配信に失敗する深刻な信頼性問題が判明した。
2026年1月、600万ドルが揺るがした1兆ドルの前提。投資効率と実用価値の二軸で問われるAI産業の真の実力
NVIDIAの四半期売上570億ドル、OpenAIのARR200億ドル。しかし2025年にはDeepSeekが600万ドルでo1同等モデルを実現し、生成AIは「幻滅の谷」に突入。企業の42%がAIプロジェクトを放棄し、Klarnaは解雇した人間を再雇用した。バブルか構造転換か — 2026年1月時点の包括的分析。